Publishing metadata#
The use of standardised metadata to describe resources is one facet of discoverability, but mechanisms to make these metadata descriptions discoverable by search applications or other machine agents is also necessary. Search applications harvest metadata to index and present in search results. In other cases a machine agent might have an identifier for a resource on the Web and want to get its metadata to learn about the content and capabilities of the resource.
Signposting#
Signposting is an approach to discovering the content and capabilities of resources accessed by resolving URIs on the Web. Like the FAIR Digital Object framework, it starts with an identifier that can be resolved, and uses typed Web links (IETF RFC8288) and IANA registered relationship types to enable an agent to discover what is identified and navigate to metadata with more information. These signposting links can implement the linking requirements of the Fair Digital Object Framework. The CDIF metadata requirements outlined below include recommended or optional properties necessary to create a FDO PID Kernel information record (FDOFIdentificationRecord in Figure 1, below) as recommended by the Research Data Alliance (RDA)(Weigel et al. (2018) ). Signposting can be used to implement FDOF requirements, and in the following implementation discussion we outline how Signposting is compatible with CDIF. The mapping from the PID Kernel information record to the CDIF metadata schema.org recommended implementation is shown in PID kernel mapping. Mapping from Signposting link relation types to CDIF metadata elements is shown in Signposting link mapping.
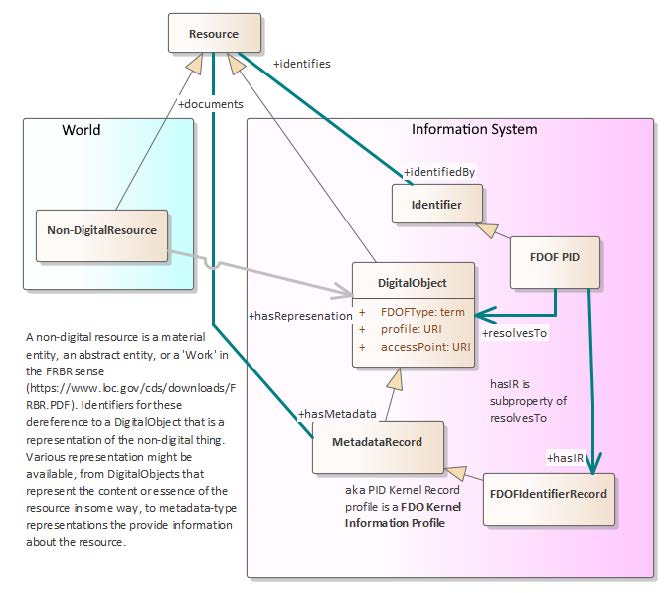
Figure 1. FDOF-CDIF metadata relations.
Search engines#
One of the drivers for the success of the World Wide Web is the emergence of search applications that use various mechanisms to traverse the Web, find Digital Objects of interest, analyse those objects to extract information about their content, and create indexes that support user searches for resources of interest. Creators and providers of Web resources (publishers) seek to increase visibility and usage of their published resources by assuring that search engines (aggregators) find and index their products. This section outlines various approaches used to make metadata accessible to search engines.
Finding documents to index: Web-crawling is still an important approach to finding and indexing resources on the Web, and this approach is supplemented by Signposting. A different and widely-used approach is the sitemap, which is a list of Web locations (URLs) for files that a hosting agent wants search engines to index. Many search engines enable providers to register sitemap locations. Alternatively, a widely-used convention on Web servers is to place a ‘robots.txt’ file in the root directory of a Web site. This file contains links that point to one or more sitemaps that should be indexed.
Getting the metadata: Once a crawler for a search application finds a document that should be indexed, it must determine if there is structured metadata to index, and what conventions the metadata uses. Possible approaches:
Each resource has an HTML landing page that describes the resource for human users, and contains embedded metadata for machine clients. Metadata can be embedded in landing pages using the HTML <script> element, in alignment with the Data on the Web Best Practices, specifically section 8.2, Metadata (See Example 1). This approach requires that each published resource has a human-readable landing page, intended to be the target of search by human users. Scripts are normally embedded in the <head> section of an HTML document. The <script> element has at minimum a ‘type’ attribute that provides a MIME-type specifying the type of script.
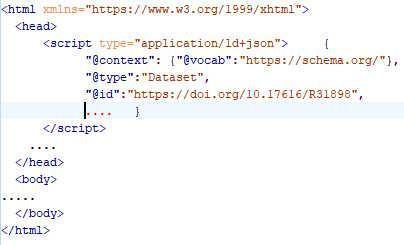
Example 1. A JSON-LD metadata object embedded as a script in an HTML document.
Metadata can be embedded in the HTML <head> section of a landing page using HTML <meta> elements, which have a ‘name’ attribute that can be used to identify different metadata properties (see Example 2). This approach has been implemented by some off-the-shelf repository software (e.g. Dataverse). The HTML <meta> elements are intended to describe the HTML document that contains the <meta> element, not some external resource that the Web page is about. CDIF recommends against this approach and suggests using the script approach (No 1 in this list) instead because that is more widely used and allows richer metadata content to be included.

Example 2. HTML meta tags with metadata about a resource.
Metadata can be linked from the landing page using the HTML <link> element in the <head> section to provide a Web locator (URL) that can be used to retrieve a full metadata document about the described resource. The link element has the “rel=’describedby’” attribute to indicate that the link is to metadata; a ‘type’ attribute to provide the MIME type of the target metadata record; and optionally a ‘profile’ attribute to identify specific metadata conventions. Note that multiple links could be provided to different metadata views, e.g. a CDIF record, a PID Kernel record, a FDOFidentifierRecord, etc. This approach depends on Web-crawlers to identify and follow these links to get the metadata that the provider wants indexed. This is one of the Signposting approaches.
The server providing the resource can be configured to include <link> elements in the HTTP response header that indicate the location of machine-actionable metadata describing the subject of the URL target. As in the HTML link approach, these links would have a “rel=’describedby’” attribute to indicate that the link is to metadata, a ‘type’ attribute to provide the MIME type of the target metadata record, and optionally a ‘profile’ attribute to identify specific metadata conventions. The advantage of this approach is that the HTTP response header links can be provided for any resource that has an HTTP URL, so links to metadata can be accessed for non-textual resources that do not have an associated HTML landing page. If the download size for the resource is large, a client can use the HTTP ‘head’ request to access this header information without downloading the entire file. This approach would enable indexing of large resource collections that have a single landing page, but for which the individual resources do not have a landing page, e.g. a STAC catalogue. The downside is that many client applications do not use the HTTP header information. This is a second Signposting approach. CDIF recommends this approach for resources that do not have landing pages; see implementation recommendations.
A sitemap can point directly to metadata documents in formats that the search engine can parse. With the basic sitemap XML schema, all metadata would need to conform to a single profile. In the implementation section below, the CDIF proposes using an extension to the sitemap scheme that allows labelled links to the indexing targets.
Another option is for the sitemap to provide a URL that retrieves a document containing a collection of metadata records, something like the US Government Data.gov Project Open Data Catalog, or Ocean Info Hub graph first approach, with individual records providing CDIF profile metadata.
How do harvesters know where to look?#
Publishers register metadata services with a harvester, e.g. by providing a URL to GET a sitemap or other metadata catalogue document, e.g. an OpenGeospatial Consortium (OGC) Record collection (catalogue).
Server robots.txt has link to sitemap.xml file; The sitemap.xml lists Web locations that a crawler should index.
Once the harvester has a URL for a location to index, how do they know where the metadata is relative to that location? Possible approaches:
Try a HTTP HEAD request on the URL and inspect. If the Content-Type header value is a known metadata type and profile, then the URL will get a document containing a single metadata record that can be indexed. Failing that, the client can look for links in the HTTP response header; if there is a link with rel=’describedby’, with a known type and profile, get the content at that link.
GET the content at the URL. Look for a <script> element with a known type and profile. Failing that, look for elements with rel=’describedby’ and a known type and profile, then get the content at that link. This general procedure can be simplified if the sitemap or other catalogue the harvester is iterating through provides labelled links.
What does the harvester do with the metadata?#
There are many possible approaches a client application could use to extract the information it needs from a metadata record. The simplest and likely most accurate approach is for the metadata to conform to a profile that the application is programmed to parse, and to communicate that profile conformance to the application. This entails two requirements. The profile must be documented in a way that allows software developers to write code to parse metadata conforming to the profile, and the profile must have an identifier that can be used to assert conformance.
The use of <script> or <link> elements (in the HTTP or HTML header) allows metadata to be offered following multiple specifications with the ‘type’ and ‘profile’ attributes used to identify the particular conventions (Example 3). Minimally, the metadata record should assert the specification used to generate the record in a metadata property.
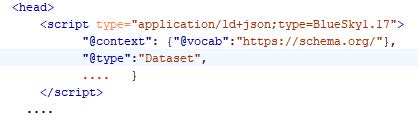
Example 3. Script with a type parameter in the MIME-type string